


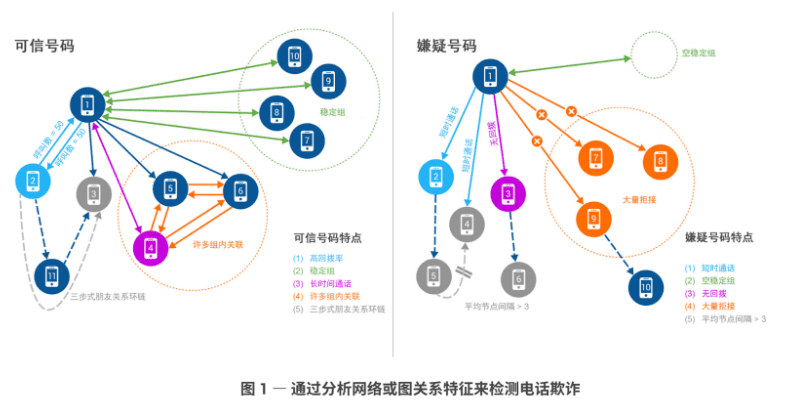
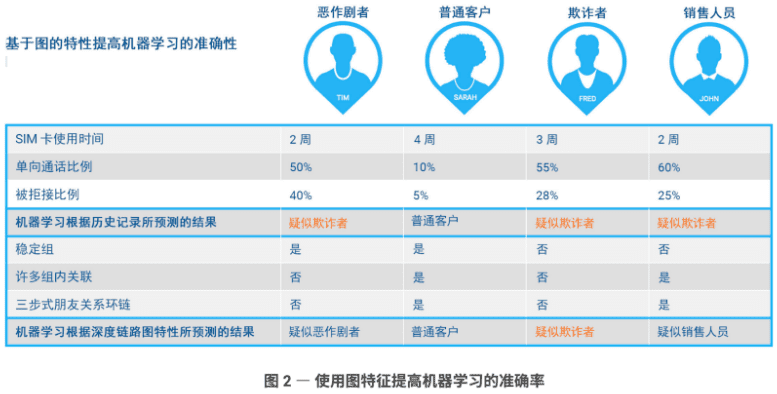
按照传统的通话记录特征,如 SIM 卡龄、单向呼叫的百分比以及被拒绝的呼叫总量百分比),四人中的三人(Tim、Fred 和 John)将被标记为疑似或潜在欺诈者,因为从这些特征来看,他们非常相似。经过分析基于图的特征,以及号码和用户之间的深度关联或多步关系,最终帮助机器学习将 Tim 归类为爱恶作剧者、John 为销售人员,而 Fred 则被标记为疑似欺诈者。我们来思考一下这个过程。
就 Tim 来说,他有一个“稳定组”,这意味着他不太可能是销售人员,因为销售人员每周都会拨打不同的电话号码。Tim 没有很多组内关联,这意味着他可能经常给陌生人打电话。他也没有任何三步式朋友关联,用于确认他所呼叫的陌生人不存在关联。根据这些特征判断,Tim 很可能是爱恶作剧者。
我们来看一下 John 的情况,他没有稳定组,这意味着他每天都通过电话寻找新的潜在销售线索。他会给具有很多组内关联的人打电话。当 John 介绍产品或服务时,如果接听方对它们感兴趣或认为与自己相关,则其中一些人很可能会将 John 介绍给其他联系人。John 还通过三步式朋友关系与他人产生关联,这表明他作为优秀的销售人员将整个环链闭合,通过在同一组内第一次联系的人的朋友或同事当中遴选,找到最终的买家来购买他的产品或服务。依据这些特征的组合,最终将 John 归类为销售人员。
就 Fred 来说,他既没有稳定组,也不与具有很多组内关联的群体交流。此外,他与所呼叫的人之间也没有三步式朋友关系。这使得他非常容易成为电话诈骗或欺诈的调查对象。
回到我们最初海底捞针的比喻,在本例中,我们可以利用图分析改善机器学习,进而提高准确率,最终找到那根“针”,即潜在的欺诈者 Fred。为此,需要使用图数据库框架对数据进行建模,以便能够识别和考虑更多特征,用于进一步分析我们的海量数据。相应地,计算机将利用越来越准确的数据进行训练,使自己不断变得聪明,更加成功地识别潜在的诈骗分子和欺诈者。
如果您正从事机器学习相关的工作,希望利用图分析来增强机器学习,别忘了点击下方的按钮,下载完整的《原生并行图》白皮书,来增强您对图的了解,从而更好地将图应用到您的工作中。
Anna Veronika Dorogus
Machine Learning Expert
Anna Veronika Dorogush graduated from Lomonosov Moscow State University and Yandex School of Data Analysis. She used to work at ABBYY, Yandex, Microsoft and Google on Machine Learning infrastructure and Machine Learning frameworks. In 2017 she published the open-source library CatBoost, which is now one of top-3 most popular Gradient Boosting libraries, and the top 7-th most used Machine Learning framework in the world according to Kaggle 2021 review.