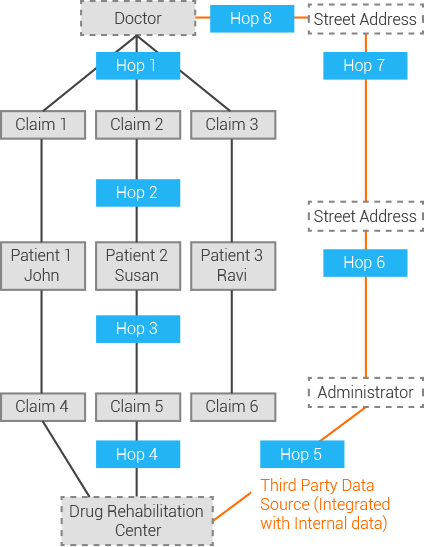
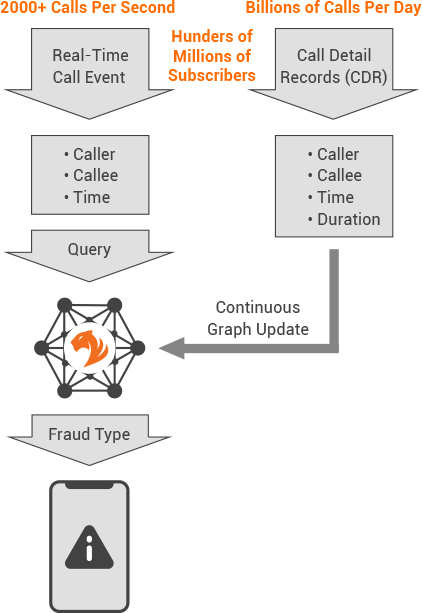
在电信总呼叫量、医疗和政府福利索赔数据或金融服务支付交易中,经证实的欺诈事件很少,不到 1%。因此,机器学习模型没有足够的训练数据,导致无法提供高准确性的欺诈检测。
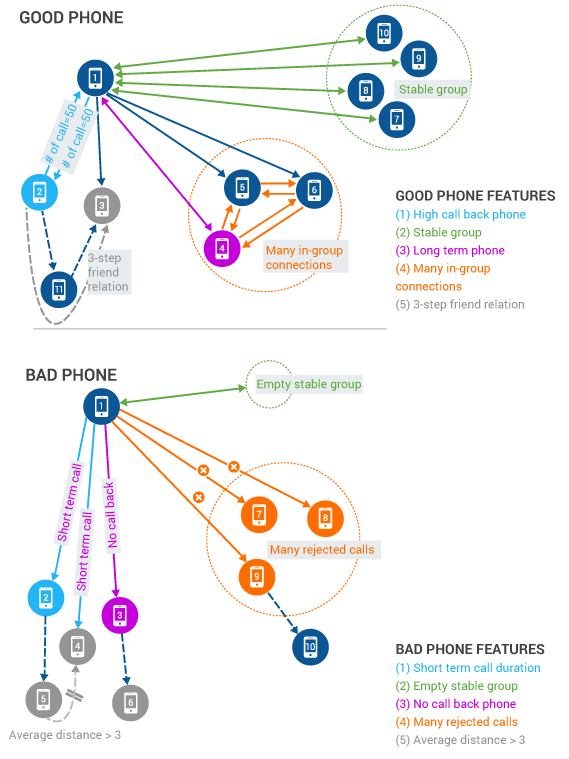
拥有原生并行架构的 TigerGraph 专用于解决这一挑战。同样以中国移动某省公司的电话欺诈检测为例,TigerGraph 对每部电话创建了超过 118 项特征属性,通过对 4.6 亿部电话相关联属性的分析,将这些电话区分为可信号码或嫌疑号码。 与此同时,它新产生的 540 亿条数据,可以作为训练数据为机器学习算法的自我提升提供支持。 这使得通过机器学习进行欺诈检测的准确性大幅提高,并同时降低了误报率和漏报率。