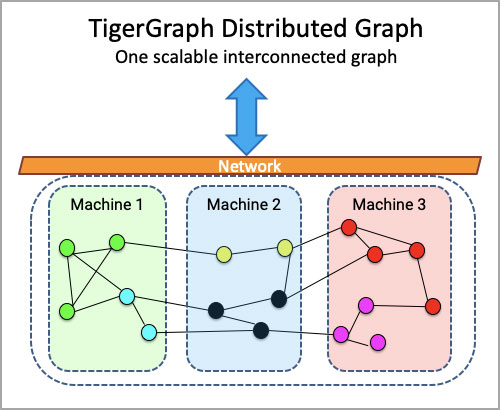
图数据库擅长解决有关大数据集内关系的复杂问题。但当数据量变得非常巨大,或问题需要深度关联分析,又或者必须实时提供答案时,大多数图数据库都会在性能和分析能力上碰壁。 这是因为前几代图数据库缺乏能满足当今速度和规模需求的技术和设计。有的不是以并行性或分布式数据库概念为核心构建的。有的则是在 NoSQL 存储之上创建图视图,虽然可以扩展到巨大的规模,但这一附加层使之丧失了巨大的潜在性能。
如果没有原生图设计,执行多步查询的代价会很高,因此许多 NoSQL 平台只能提供很高的读取性能,而不支持实时更新。原生分布式图可实现深度关联分析,加快数据加载速度以快速构建图,加快图算法执行速度 ,能够实时流式处理更新和插入,能够将实时分析与大规模离线数据处理统一起来,能够纵向扩展和横向扩展分布式应用。